���ڱ��������Ϣ���뿴����ٷ���վ��http://restfulwebservices.cn/ ������ ������Դ�ļܹ�
���Ѿ�����չʾ��REST�������������һ�û��ϵͳ�ؽ����������������γɵģ��Լ������չ�ָ������� ����һ�£��ҽ�����һ�������RESTʽ�ܹ�����������Դ�ļܹ���Resource-Oriented Architecture��ROA���� ROA��һ�ְ�ʵ������ת����RESTʽWeb����ķ���������URI��HTTP��XML���и�����WebӦ��һ���Ĺ�����ʽ�������Ա������ʹ�����ǡ�
�ڵ�һ�£��Ҹ���RESTʽWeb����RESTful web services�������������ϵIJ�ͬ�����������ǽ��з��ࡣ ����������ֱ��Ӧ��REST���ĸ���־�����е�������
• ��������Ϣ��scoping information���������������͵�Ϊʲô����Щ���ݣ��������������ݡ�����������Ϣ�Ƿ���URI��ġ����ǿ�Ѱַ�ԣ�addressability��ԭ��
• ������Ϣ��method information������Ϊʲô������Ӧ�����Ͷ�����ɾ����Щ���ݣ�������������Ϣ�Ƿ���HTTP������ġ� HTTP����ֻ���������֣��������˶�����֪����Щ���������á�����ͳһ�ӿڣ�uniform interface��ԭ��
����һ�£��ҽ�����������Դ�ļܹ���ROA���Ĺ��ܳɷ֣���Դ����Դ���ơ���Դ�ı�ʾ����Դ������ӡ� �ҽ����Ͳ�����ROA�����ԣ���Ѱַ�ԣ�addressability������״̬�ԣ�statelessness������ͨ�ԣ�connectedness����ͳһ�ӿڣ�uniform interface���� �ҽ�չʾWeb������HTTP��URI��XML�������ʵ����Щ���ܳɷ֡��Ի���������Եġ�
��ǰ�漸�£���ͨ�����е�һЩWeb������S3������˵����һЩ��� �ڱ��£��ҳ��˻�����һЩ���е�Web����web services�����⣬��������һЩ���е���վ��web sites���������� ϣ���˿����Ѿ��������š���վ����Web����������WebӦ�ã������������棩����RESTʽWeb�����ˡ� ���ڽ���һЩ���������Ѱַ�ԣ�ʱ�������һЩ��ʵ��URIs��������Ϳ���ͨ�����������������ЩURIs����������йظ����ˡ�
������Դ�ļܹ���
ΪʲôҪ����һ���´ʡ�������Դ�ļܹ���Resource-Oriented Architecture��ROA�����أ� Ϊʲô��ֱ����REST�� �š���ȷʵ�ڱ���ķ������ᵽREST����������Ϊ����������Դ�ļܹ�Ҳ����REST���
���ǣ�REST������һ�ּܹ�������һ�����ԭ�� ����Խ�����������Щԭ���棬һ���ܹ����ñ���һ���ܹ��á��������㲻�ܽ���REST�ܹ�������Ϊ������һ���С�REST�ܹ����Ķ�����
ֱ��ĿǰΪֹ�������Ѿ�ϰ��������Ʒ���ʱ�����������Լ���REST�����ⷢ��һ���Լܹ���one-off architectures���� �������������Ľ�����Dz����˸�ʽ������REST-RPC���Web�����䴴�����ǻ���������ΪRESTʽ�ġ� Ϊ�ˣ��������һ�鹹������RESTʽWeb����ľ�����������ܹ�������һ״���� �ڽ�������������һ����һЩ�IJ��裬��ֻҪ������Щ������ܰ�����ת����һ������Դ��resources���� �����㲻ϲ���ҵĹ��������ٿ���֪������Щ�ı��Dz��ᵼ��Υ��REST���ġ�
��Ϊһ�����ԭ��REST�Ƿdz�ͨ�õġ� �����˵������������Web�� REST��������HTTP���ƻ�URI�ṹ�� ����Ϊ�����۵���Web�����������ص���Web��ؼ���������������Դ�ļܹ���ROA�����������ض��ı��������̽�������HTTP��URI��ʵ��REST�� ���罫�����ַǻ���Web��RESTʽ�ܹ����������ʵ����best practices������ROA�IJ�ֻ࣬�Ǿ���ϸ�ڻ��е��� ��ʱ���ǻ��а취����ġ�
REST�Ĵ�ͳ����������һЩ�հף����ʵ�����Ǵ����˴������䴫�ԣ�folklore���Ļ����� ��������Roy Fielding�IJ�ʿ���ļ�W3C��ر��Ļ����ϸ���һ��������ϣ���Բ���������һ���˽ᣬ����Щ���䴫������Ϊһ����ȷ��������ʵ���� ����REST��һ�ּܹ�����REST���ƺ��ҵļܹ�Ҳ�Dz���ƽ�ġ� �һ���Լ���ʵ�������뽨�飬����Щ����Web�������뷨���������
�����ROA����´ʵĸ���ԭ���ǣ���REST������ʱ�̫��������ɱ�֮��� ����ij���ᵽ����ʣ���ͨ����ʾ�ţ�����������ͬ�ļܹ�����������RESTʽ�ܹ�������ͬ���RESTʽ�ܹ��������Դ˳������顣 ����REST������һЩ�������⣨����URI��HTTP�ļ�ֵ�����ѻ������һ�£���REST�������Ǵ����Ų�ͬ�ɱ�
�������״����û���ɱ�֮�������ǣ�̫��ľ�������ң���ƾ��Ը�����ܽ������� ���ԣ���Ҫ���ҵĹ��ڡ�Ӧ��������RESTʽӦ�á���˼��ȡһ����ͬ�����֡� ��������һ�ҵ���Щ�뷨�����ɱ�����õ��ɱ�֮���У���Щ��ͬ���ҵ��˾Ϳ�������ҵ�������Դ�ļܹ���ROA���������Ǹ�RESTʽ�ܹ���һ���REST��Ϊһ̸�� ��Ҫ�Ѹ��������ˣ��ſ����������⡣
��������Դ�ģ�resource-oriented�����͡�������Դ�ļܹ���resource-oriented architecture���������Ĵ���Ѿ�����������һ���RESTʽ�ܹ��ˡ�* �ҳ��ϡ�������Դ�ļܹ���������ȫ����ԭ���Ĵʣ����ҵ��÷�����ǰ���÷��պ��Ǻϣ������Ҿ��ò�������ʱ����ƴ�������RESTҪ�á�
���ڱ��������Ϣ���뿴����ٷ���վ��http://restfulwebservices.cn/
ʲô����Դ��
�κ����ֻҪ���б����õı�Ҫ��������һ����Դ��resource���� �������û�����Ϊ������һ�����ı����ӣ���������һЩ���ԣ���ȡ�����ı�ʾ����������ʾ���������һ���֣���ע�����ȵȡ�����ô��Ӧ�ý�����Ϊһ����Դ��†
ͨ����һ����Դ����ij�����Դ���ڼ�����ϲ�����Ϊ��������������磺һ���ĵ������ݿ����һ����¼����������ij�㷨�Ľ���ȵȡ� һ����Դ��resource��������һ��ʵ�����һֻƻ������Ҳ������һ������ĸ�������������������������ǽ������ģ�������Դ�ı�ʾ��representation���϶��������Ǵ�ʧ������
������һЩ��Դ�����ӣ�
* ij������1.0.3��
* ij���������°汾
* 2006��10��24�շ����ĵ�һƪ��������
* һ�Ű���ɫ��Сʯ�ǵĵ�ͼ
* ����ˮĸ��һЩ��Ϣ
* ��ˮĸ�йص���Դ�б�
* ����1024��������
* ����1024�ĵ���С����
* 2004���4���ȵ�����
* Alice��Bob����֮��Ĺ�ϵ
* bug���ݿ���Ĵ����bug�б�
URIs
��ʲô������Դ�Ƶ�����һ����Դ�� ������������һ��URI�� URI������Դ�����ƣ�Ҳ����Դ�ĵ�ַ�� ���һ����Ϣû��URI�����Ͳ�������һ����Դ��Ҳ������������Web�ϣ���ֻ������������һ����Դ��һЩ���ݡ�
* ����֪��������ʹ�á�������Դ��һ�ʵ����ӣ���2004��James Snell��IBM developerWorks�Ϸ�����һƪ���£���Resource-oriented vs. activity-oriented Web services����http://www-128.ibm.com/developerworks/xml/ library/ws-restvsoap/����2006��8�£����鷢��֮ǰ����Alex Bunardzicʹ���ˡ�������Դ�ļܹ���Resource-Oriented Architecture��������ʣ�http://jooto.com/blog/index.php/2006/08/08/replacing-service-oriented-architecture-with-resource-oriented-architecture/������Ȼ�Ҳ�����ȫ��ͬ��Щ�����еĹ۵㣬���ҳ�����������֮ǰʹ���˸����
* ��The Architecture of the World Wide Web����http://www.w3.org/TR/2004/REC-webarch-20041215/#p39�����кܶ�ֵ�òο������ݣ� ��������������Ӧ�����ţ�ΪӦ�÷���URI��������ģ���ʹ�����Ч�ò������ԡ��� ����ʵ������ΪROA�Ŀںš�
���ǵ�����ǰ����ΪHTTP 0.9�ٵ��Ǹ��ͻ���������������������� �������ȡhttp://www.example.com/hello.txt��HTTP 0.9����Ϊ����
�ͻ������� ��������Ӧ
GET /hello.txt Hello, world!
HTTP�ͻ���������������Դ�ģ��������ӵ�����Դ���ڷ�������������www.example.com����Ȼ����÷��������ͷ�������GET����������Դ��·������/hello.txt������ ��Ȼ���ڵ�HTTP 1.1��HTTP 0.9������һЩ�������ǵĹ���ԭ����һ���ġ�������������·��������Դ��URI�
�ͻ������� ��������Ӧ
GET /hello.txt HTTP/1.1
Host:www.example.com
200 OK
Content-Type: text/plain
Hello, world!
Tim Berners-Lee��Universal Resource Identifiers��Axioms of Web Architecture ��http://www.w3.org/DesignIssues/Axioms����ƪ������ܺõظ�����URI�����ԭ�����һ��ڱ�����ϸ�����URI��Ϊ��Դ����URI��ԭ����
URI��Web�Ļ��������� ���ı�ϵͳ��HTML֮ǰ�����ˣ�ͬ���أ�InternetЭ����HTTP֮ǰҲ�Ѿ������ˡ�������ǰ����������֮����û����ϵ�ġ���URI��������ЩInternetЭ�黥���������γ�Web������ͬTCP/IP�Ѹ������磨Usenet��Bitnet��CompuServe�ȣ������������γ�Internetһ���� Ȼ��Web��������ЩЭ�飬�����������ǣ����Internet��˽������������һ����
����������Web��������Gopher�������Ǵ�Web��������FTPվ�㣩�������ļ���������Web��������WAIS�������������������Web��������Usenet�����飩�Ͻ�̸�� �汾����ϵͳ����Subversion��arch�ȣ�Ҳ�ǻ���Web�ģ������Dz���ר�е�CVSЭ�飩�� ������EmailҲ��ת��Web�ˡ�
Web֮�����ܹ�������Э����������Ϊ����ȡ��һ�ּķ�ʽ����������Դ����ǩ����������������Э����û�еġ� Web�ϵ�ÿ����Դ��������һ��URI�� �����URIд�ڻ��������ϣ� ���ǿ��Կ����Ǹ�����ƺ�����Web���������Ǹ�URI��ֱ�ӽ������������ǽ������Դ�� ���ƺ��Ƚϲ���˼�飬����URI������֮ǰ����������˾�ռ��ߵĽ����Dz�����ʵ�ֵġ�
���ڱ��������Ϣ���뿴����ٷ���վ��http://restfulwebservices.cn/
URIӦ����������
����ROA��Roy Fielding�IJ�ʿ���ļ�W3C�Ƽ�����recommendations��[ ]��Ϊ������Ľ���֮������ĵ�һ�㡣 �ҽ��飬��Դ����URIӦ�ø�����ֱ���ϵĹ����� ����ǰ���Ҹ�������Դ��������һЩ������URIs��
* http://www.example.com/software/releases/1.0.3.tar.gz
* http://www.example.com/software/releases/latest.tar.gz
* http://www.example.com/weblog/2006/10/24/0
* http://www.example.com/map/roads/USA/AR/Little_Rock
* http://www.example.com/wiki/Jellyfish
* http://www.example.com/search/Jellyfish
* http://www.example.com/nextprime/1024
* http://www.example.com/next-5-primes/1024
* http://www.example.com/sales/2004/Q4
* http://www.example.com/relationships/Alice;Bob
* http://www.example.com/bugs/by-state/open
URIӦ����һ���Ľṹ�� ��Ȼ����URI������ͬ��������Ӧ����һ����ģʽ������/search/Jellyfish�����ڻ�ȡ�й�ˮĸ����Ϣ��URI����ô���ڻ�ȡ�й��������Ϣ��URI��Ӧ����/search/Mice��������/i-want-to-know-about/Mice�� ����ͻ���֪��һ�������URI�Ľṹ����ô���Ϳ���ͨ������URI�����ʸ÷����ͻ�����ʹ����ķ����棬�������輫������ɣ��������ܴ�������������ʹ�÷�ʽ��
������������һ�µġ�������Դ��һ���н������ģ��Ⲣ����REST�ıر����� �Ӽ����Ͻ���URI���Ƿǵþ߱�һ���ṹ��ģʽ��������Ϊ��Ҫ������ ���õ�Web�����Ҫ��������RESTʽ����ϼܹ�����Ҳһ����
URI����Դ�Ĺ�ϵ
����������һЩ���˵����ӣ�������Դ�п�����ͬһ���� ����URIs����ָʾͬһ����Դ�� һ��URI����ָʾ������Դ��
���ݶ��壬�κ�������Դ����������ͬһ���� ������������������Դ��ͬһ������ôʵ��������˵��ֻ��һ����Դ�� ������������ͬ����Դ��ijһʱ��ָ��ͬ�������ݣ������п��ܵġ� ���赱ǰ�����汾Ϊ1.0.3����ôhttp://www.example.com/software/releases/1.0.3.tar.gz��http://www.example.com/software/releases/latest.tar.gz����һ��ʱ����ָ��ͬһ���ļ��� ��������URIs�����岻ͬ��һ������ָ��ijһ�ض��汾����һ������ָ��ǰʱ�̵����°汾�� �����������������Դ�� ������Ҫ����һ��1.0.3���bug���㲻Ӧ��ʹ��ָ�����°�����ӡ�
һ����Դ������һ������URI�� λ��http://www.example.com/sales/2004/Q4��������ϢҲ�������һ��URI http://www.example.com/ sales/Q42004�� һ����Դ�ж��URIs�ĺô��ǣ��ͻ��˶Ը���Դ�����ñ�ø����ף������ǣ�ͬһ��Դ���ж��URI��������ϡ��ЧӦ�����еĿͻ��������URI���еĿͻ������Ǹ�URI���������Զ���֤��ЩURIs��ָ��ͬһ����Դ�ġ�
һ�ַ����ǣ�������Դ�ж��URIs����ôѡ������һ����Ϊ����Դ�ġ��淶��URI�� ���ͻ�������ù淶URIʱ��������������Ӧ����200����OK��������������ȷ�����ݣ����ͻ�����������URIʱ��������������Ӧ����303����See Also����������������Դ�Ĺ淶URI�� ��Ȼ�ͻ�������ƾ��۵�֪������URIs�Ƿ�ָ��ͬһ��Դ���������Էֱ���������URI����һ��HEAD�����Ƿ�����һ��URI�ض�����һ�������߶��߶��ض�������URI��
����һ�����������Ƕ�������ЩURIһ��ͬ�ʡ���ͬ������Ӧ�����Ƕ��ڷǹ淶URI����������Ӧ��ͷContent-Location��������淶��URI��
��Ϊ sales/2004/Q4 �� sales/Q42004 ��ͬһ����Դ��2004���4����������Ϣ���IJ�ͬURIs�������㽫��������URIs�����ͬ���ֽ����� ��Ȼ releases/1.0.3.tar.gz �� releases/latest.tar.gz �Dz�ͬ����Դ��ǰ�߱�ʾ��1.0.3�桱�����߱�ʾ�����°桱����������Ҳ���ܻ᷵����ͬ���ֽ�����
һ��URIֻ��ָʾ��designate��һ����Դ�� ����һ��URIָʾ�����Դ�Ļ������Ͳ���ͳһ��Դ��ʶ����Universal Resource Identifier���ˡ� ��������������һ��URIʱ�����������Է��ظ�����ڶ����Դ����Ϣ�����������������Դ��Ҳ�������������Դ����Ϣ�� �����ȡһ����ҳʱ��һ�������ֻ���ظ���ҳ��һЩ��Ϣ��������Ҳ�����һЩָ��������ҳ�����ӡ� ������Amazon S3�ͻ��˻�ȡһ��S3Ͱ��bucket��ʱ���㽫�õ�һ���ĵ������мȰ������ڸ�Ͱ����Ϣ��Ҳ�������������Դ����Ͱ��Ķ�����Ϣ��
��Ѱַ��
���Ѿ�����Դ����Դ��URI���˽��ܣ������ҿ��Խ�һ��̽��ROA�����������ˣ���Ѱַ�ԣ�addressability������״̬�ԣ�statelessness����
���һ��Ӧ�ý������ݼ����м�ֵ�IJ�����Ϊ��Դ��resources��������������ô��Ӧ�þ��ǿ�Ѱַ�ģ�addressable���� ��Ϊ��Դ��ͨ��URI��¶�ģ�����һ����Ѱַ��Ӧ�û�Ϊ�������ṩ��ÿһ����Ϣ������һ��URI�� һ����˵��URI�����������ġ�
�������û��Ƕ���������Ѱַ�ԣ�addressability�����κ���վ��WebӦ����˵����������Ҫ�ķ��档 �û��ܴ�����ֻҪ�����г�ֵļ�ֵ��������һЩȱ�ݣ�����Ҳ�������⡢�����а취��ͨ�������粻�߱���Ѱַ�ԣ��û���û���ˡ�
����һ��ָʾ��designate�����й�ˮĸ����Դ�б��������Դ��URI��http://www.google.com/search?q=jellyfish�������Google������ˮĸ��jellyfish����URI�� http://www.google.com һ��������ʵ��URI�����ǣ�����HTTP���ǿ�Ѱַ�ģ�����Google�������治�ǿ�Ѱַ��WebӦ�ã���ô�Ҿ���������ֱ�Ӹ������URI�ˡ�����ֻ�ܸ����㣺�����������google.com���������������롮jellyfish����Ȼ������Google ��������ť����
�ⲻ��ѧ���ϵĵ��ǡ� ��90������� ftp:// URI��������֮ǰ����ʱ����ֻ������д������FTP������½ftp.example.com��Ȼ����� pub/files/ Ŀ¼���������ļ� file.txt����URIʹ��FTP���и�HTTPһ���Ŀ�Ѱַ�ԡ� ��������ֻҪд������ftp://ftp.example.com/pub/files/file.txt�������ˡ� ��Ȼ�ڼ����ϲ��軹��һ���ģ���������Щ��������ɻ����Զ�����ˡ�
��ΪHTTP��Google���ǿ�Ѱַ�ģ������ҿ��������и�����URI�� ��������������ַ�����������URI����ֱ�ӽ���Google����Ӧ�õ��ض�״̬��
ҳ���֮������Ѹ�ҳ�������ǩ���Ա��Ժ�ʹ�á� ��������Լ�����ҳ���ṩ����URI�����ӡ� �㻹����ͨ��Email�Ѹ�URI���߱��ˡ�������HTTP���ǿ�Ѱַ�Ļ�������ֻ�а�����ҳ������������Ȼ��HTML�ļ���Ϊ�������������ˡ�
Ϊ�˽�ʡ�����������Ϊ��ı�����������һ��HTTP�������棨proxy cache���� ����һ���������� http://www.google.com/search?q=jellyfish ʱ���û��潫�ڱ��ر���һ�ݸ��ĵ��ĸ��������´������ٷ���ͬ����URIʱ���û����ֱ�ӰѸø������������ߣ���������������һ�Ρ� ��һ�е���ʵ�֣�Ҫ��ÿ��ҳ�涼��һ��Ψһ�ı�ʶ������һ����ַ��address����
һ��URI������Ϊ��һ��URI�����롣 ���磬�������һ���ⲿWeb��������֤ij����ҳ��HTML�����Ƿ���Ϲ淶�����߰�ij����ҳ����ı�����Ϊ��һ�����ԡ� ��ЩWeb������URI��Ϊ���롣 ����HTTP���ǿ�Ѱַ�ģ������������������ϣ�����ĸ���Դ���в����ˡ�
��Amazon S3�ÿ��Ͱ��bucket����ÿ������object�������Լ���URI������S3�����ǿ�Ѱַ�ġ� ��δ������Ͱ�������Ȼ��������Դ��������Ҳ���Լ���URI�������ͨ��������URI����PUT��������������Դ��
��ļ�����ϵ��ļ�ϵͳҲ��һ����Ѱַ��ϵͳ��������Ӧ�ÿ��Խ����ļ�·��Ϊ������Ȼ��Ը��ļ�����һЩ������
���ӱ�����ĵ�Ԫ��Ҳ�ǿ�Ѱַ�ģ�������ڹ�ʽ�����õ�Ԫ��������ʽ����ֵʱ�ͻ��õ������õĵ�Ԫ���ֵ�� URI�ͺñ�������ļ�·���͵�Ԫ��
��Ѱַ�ԣ�addressability����WebӦ�������ŵ㣬����ͻ��˿���������ɵ�ʹ����վ���������ܴ����������վ����������ʹ�÷�ʽ���� ���տ�Ѱַ�Թ������������û�����REST�ĺܶ��ŵ㡣 REST-RPC������˳�����ԭ������ڣ����ǰѿ�Ѱַ�Ը����̵��ñ��ģ�ͣ�procedure-call programming model����������ˡ� ���ڡ�Resource-Oriented Architecutre���аѡ�resource��д����ǰ�棬����Ϊ�߱���Ѱַ�Ե�����Դ��
WebӦ���ǿ�Ѱַ�ģ����ƺ���������Ȼ�ġ����ǣ�����WebӦ��ȴ���ǿ�Ѱַ�ģ�������AjaxӦ�á� �����ҽ��ڵ�ʮһ��˵���ģ������AjaxӦ��ֻ�ǵ���RESTʽ����Web����Ŀͻ��ˣ����������������վ��ʹ��ʱ����ᷢ��������վ�ĸо���̫��
�ҾͲ������ﷴ�����������ˡ������Ǽ�������Google���Ե����ۣ�������������Gmail����Email���� �������û�������Gmail��URIʼ����https://mail.google.com/����������ʲô�������������Gmail��ȡʲô��Ϣ������Gmail�ϴ�ʲô��Ϣ���㲻�ῴ�����URI�� ������ˮĸ�ĵ����ʼ�ѶϢ����һ��Դ���ǿ�Ѱַ�ģ���ǰ���ᵽ�ġ��й�ˮĸ����Դ�б��������Դ�ǿ�Ѱַ�ġ�‡ �����������ҽ��ڵ�ʮһ����չʾ�ģ���GmailӦ�ñ������һ����Ѱַ����վ������������й�ˮĸ�ĵ����ʼ�ѶϢ�������Դȷʵ��һ��URI���� https://mail.google.com/mail/?q=jellyfish&search=query&view=tl�������ǣ�����վ������ֱ��ʹ�õģ�����վ��һ����ʵ��Web������������������һ�����������������е�JavaScript���� Gmail Web�����ǿ�Ѱַ�ģ��������ø÷����Gmail WebӦ�ò��ǿ�Ѱַ�ġ�
���ڱ��������Ϣ���뿴����ٷ���վ��http://restfulwebservices.cn/
��״̬��
��Ѱַ����ROA���ĸ���Ҫ����֮һ�� ROA�ĵڶ�����������״̬�ԣ�statelessness���� �һ����������״̬�ԵĶ��壺һ����Ϊһ���ԵĶ��壬��һ�����к�ROAʵ�ʵĶ��塣
��״̬�ԣ�Statelessness����ζ��ÿ��HTTP��������ȫ�����ġ� ���ͻ��˷���һ��HTTP����ʱ�����������������ʵ�֣�fulfill�������������ȫ����Ϣ���������������κ�֮ǰ�����ṩ����Ϣ�� ���豾��������Ҫ֮��ij�������ṩ����Ϣ����ô�ͻ���Ӧ�����Ǹ���ϢҲ�����ڱ��������
‡ Gmail��һ����Ѱַ�İ汾��λ��URI https://mail.google.com/mail/?ui=html��������������HTML�ӿڵĻ�����ô������ˮĸ�ĵ����ʼ�ѶϢ�������Դ���ǿ�Ѱַ���ˡ�
�� Python��libgmail�⣨http://libgmail.sourceforge.net/��Ҳ���Ե������Web����
��ʵ�ʵأ����Ǵӿ�Ѱַ�Է�����������״̬�ԡ� ��Ѱַ��Ҫ�����������ṩ��ÿһ���м�ֵ����Ϣ��Ӧ����Ϊ��Դ������������ÿ����Դ�����Լ���URI����״̬��Ҫ���������ܵ�״̬Ҳ����Դ��ҲӦ�����Լ���URI�� �ͻ��˲���Ϊ����ij������ɱ����������ܶ���ʹ����������ij״̬��
��human web�ϣ��㾭����������������������������ġ����أ�back������ť���������ˣ���������������ʷ��ǰ�������ˡ� ��ʱ��������Ϊ��ִ����һ�����ɳ����IJ��������緢����һƪ�������£�������һ���飩�����������������������������վΥ������״̬��ԭ����վ�����㰴��һ����˳���������������ȷ�A�����ٷ�B����Ȼ���ٷ�C���������ڷ���B������ַ���һ��B������������������C������ô���������������Ϊ��
����������һ�����������ӡ� ����������һ����������״̬��Web�������ٶ�����������ÿ������������һ����֮��Ӧ��״̬��ÿ��״̬�����Լ���URI�� �������URI http://www.google.com/search?q=mice ��÷�������һ���й�����mice������Դ�б��� �������URI http://www.google.com/search?q=jellyfish ��÷�������һ���й�ˮĸ��jellyfish������Դ�б��� �����д�������URI��������ȴ� http://www.google.com/��Ȼ����д����ִ��������
���������й�������й�ˮĸ����Դ�б�ʱ������һ�λ���������б��� ����ȵõ��б��е�һҳ���������10����������������Ϊ����IJ�ѯ��Ϊƥ��Ľ���� ��������ø�����������Ҫ����һ��HTTP���� �ڶ�ҳ������ҳ���Ǹ�Ӧ�õIJ�ͬ״̬������������Ҫ���Լ���URI������http://www.google.com/search?q=jellyfish&start=10������ͬ���п�Ѱַ����Դһ������Ӧ��״̬Ҳ�ɱ����������ˡ���������߱�������ǩ���Ա��Ժ�ص���״̬����
ͼ4-1��һ����״̬ͼ������ʾ��һ��HTTP�ͻ����������һ������������ĸ�״̬���н����ġ�
��Ϊ�ͻ���ÿ������ص������״̬����������һ����״̬��Ӧ�á� ����������������ġ� �ͻ��˿��������������Щ��Դ������������� �������������2ҳ֮ǰ�����1ҳ�����߸����������1ҳ�����������Դ˲�����⡣
��Ϊ�Աȣ�ͼ4-2�����˼�����������������һ����״̬��Ӧ�õ����Σ�һ��״̬�ƽ�����һ��״̬��������������Ӧ��������
����HTTP�����Ϊ������״̬�Ľ�������ôHTTP�������ࣺ���ͻ�������һ����������Ựʱ��������������Զ����������������ؿͻ��˷�������������Ϊ�������汣���иÿͻ����ϴ������ļ�¼������ͻ������ڲ鿴ǰ10�����������Ҫ����11��20���������ôֻҪ����һ����start=10������������ˣ������ط��� /search?q=mice&start=10���ظ�֮ǰ��������Ҫ�����������˵Ҫ��������
 ���������ͼƬ���£�
���������ͼƬ���£�
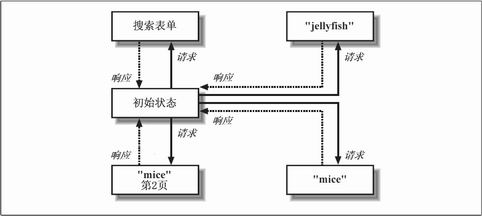
ͼ4-1 һ����״̬����������
���������ͼƬ���£�
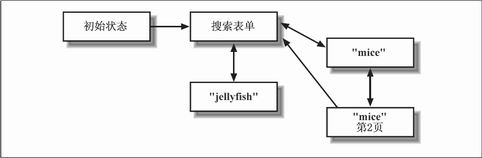
ͼ4-2 һ����״̬����������
FTP���������ġ�FTP��һ��������Ŀ¼��working directory�����ĸ��������ı������������������Ự�����в���仯�� ����Ե�¼һ��FTP����������cd�������ij��Ŀ¼��Ȼ����get��������һ����Ŀ¼�µ��ļ��������Ҫ����ͬĿ¼�µ������ļ���ֱ����get�������ؾ����ˣ�����Ҫ������cd�������Ŀ¼�� Ϊ��HTTP��֧�������أ�
״̬���Լ���HTTP��������������HTTPЭ���ø��Ӹ��ӡ� FTP�ͻ���Ҫ��HTTP�ͻ��˸������࣬ԭ������ڿͻ��˺ͷ������ĻỰ״̬����Ҫ����ͬ���� ��ʹ�ڿɿ��������ϣ���Ҳ��һ��ӵĹ������ο�Internet������һ���ɿ������硣
��Э����ȥ��״̬���������ٳ��������� ��Ϊÿ�ν�����ֻ���������������Է���������Ϊ�ͻ��˳�ʱ�����ǡ�
��Ϊ�ͻ��˷�����ÿ�������ﶼ����ȫ��������Ϣ�����Է��������������ͻ���������״̬�� ��������֡���Ϊ������������ij��û�и��߿ͻ��˵�״̬�������¿ͻ����ڴ���ġ�����Ŀ¼����ִ�в������������
��״̬�Ի�������һЩ�����ԡ� �ڸ��ؾ��⣨load-balanced���������Ϸ�����״̬��Ӧ�ý��������ࣺ��Ϊ��������֮��û����������������ǿɱ����ڲ�ͬ�ķ������ϴ����������������֮�����κ�Э����Ҫ������ģ��ֻ�������ؾ���ϵͳ�����ø�������������ˡ� ����״̬��Ӧ��������Ҳ�DZȽ����ģ�ֻҪ��һ�����Ϳ��Ծ����Ƿ�Ҫ����һ��HTTP����Ľ���ˣ�ǰһ�������״̬����Ӱ��Ե�ǰ����Ļ��洦����
�ͻ���Ҳ������״̬���л��档 �ͻ��˿������������50ҳ�йء������������ʱ���ѵ�ǰURI��/search?q=mice&start=500��������ǩ�����������ͻ��˿�����һ�ܺ�ػص����״̬��������������������ǰ���״̬�� ��һ��HTTP�Ự�ᆳ����Сʱ��õ�����ЧURI���������»Ự��ֱ�ӷ��ʣ�����ͬ����Ч��
Ҫ����ķ���߱���Ѱַ�ԣ�addressability��������Ҫ����һЩŬ������Ӧ�õ����ݻ���Ϊ��Դ�ļ��ϡ� ����HTTP������һ����״̬��Э�飬�������д��Web����Ĭ�ϵؾ߱���״̬�ԣ�����Ҫ����һЩŬ�����ı�����
�ı���״̬�ԣ���÷�����������HTTP�Ự��session���� ��һ���û��״η��������վʱ������õ�һ��Ψһ���ַ��������Ա�ʶ���ڸ���վ�ϵĻỰ�� ����ַ������Ա�����cookie�Ҳ���Է��ڸ����û�������URI� ����һ��RailsӦ�����õĻỰcookie��
Set-Cookie: _session_id=c1c934bbe6168dcb904d21a7f5644a2d; path=/
����һ��PHPӦ����URI������ỰID�����ӣ� http://www.example.com/forums?PHPSESSID=27314962133��
ֵ��ע���ǣ���Щ�������ʮ�����ƻ�ʮ�����ַ���������״̬�� ״̬�����ڷ������˵�ij�����ݽṹ���Щ�ַ���ֻ�Ǹ����ݽṹ�ļ���key���� ��״̬��URIs��stateful URIs������Υ��REST��������ͨ�����ַ�ʽ����һ��״̬���߿ͻ��ˡ� �����ǣ�cookies���е�Υ��REST����ģ��һ��ڵڰ��¡�Cookies�����⡱һ������ϸ̸������ cookie���Web����ͻ��˲�������ͬWeb������ġ����أ�back������ťʧ�顱һ����Ӱ�졣
����Google�������淵�ص�һ��HTML��ҳ����һ��URI����URI�������ѯ���� start=10�� Ҳ����˵����������ͻ��˷�������һ����ѡ��״̬��
����ЩURI�ð���������״̬���У������ǽ�����һ�����������ڷ������ϵ�״̬��Ϣ����Ӧ�ļ���key����start=10��������һ�����壬��PHPSESSID=27314962133��RESTʽ�ܹ�Ҫ���״̬�����ڿͻ��ˣ������ڷ�����������ÿ�������ж�������Щ״̬��������Ҫ�Ļ�����
����������ͨ����ͻ��˷�����״̬��URIs��stateful URIs��Ϊ�ͻ����ṩ������״̬�Ļ��ᣬ���������Լ���Ӧ�����κ�״̬��
���ڱ��������Ϣ���뿴����ٷ���վ��http://restfulwebservices.cn/
Ӧ��״̬ VS ��Դ״̬
������̸�ۡ���״̬�ԡ�ʱ����ʲô��Ϊ��״̬���أ� ���ǵ���Web��������Ϊ��������ṩ��������Ҫ�����ݣ���ô�������˵ij־û����ݣ�persistent data����������Ǽ������Ᵽ���ڷ���˵�״̬��state���к������أ� Flickr Web�������������Լ����ʻ��ϴ�ͼƬ����ЩͼƬ�DZ����ڷ������ϵġ� ���ǣ�����������ڲ��÷����������κ�״̬��Ŀ�ģ���Ҫ��ͻ����ڷ���flickr.com��ÿ�������ﶼ��������ͼƬ���Ǿ�̫�鷳�ˡ� �ǽ�����÷��������Ŀ�ꡣ ����һ��������ǰ�����ᵽ���Ǹ������Ų�Ӧ���ڷ������ϵĿͻ��˻Ự״̬���кβ�ͬ�أ�
����һ����������⡣ ��״̬�ԣ�statelessness����ζ�ţ���һ��״̬���Ƿ�������Ӧ����ġ� ʵ���ϣ�״̬�����֡� �����ڿ�ʼ���ҽ�����Ӧ��״̬��application state������Դ״̬��resource state����ǰ��Ӧ�ñ����ڿͻ��ˣ�����Ӧ�ñ����ڷ���ˡ�
����ʹ����������ʱ�������������͵�ǰҳ�������Ӧ��״̬����Щ״̬����ͻ��˶���ģ��������������ˮĸ����������ĵ�3ҳ�������������������������ĵ�1ҳ�� ��������ʹ����������Ĺ켣��ͬ���������ǵ����������뵱ǰҳ�벻һ���� ���Ǹ��ԵĿͻ��˷ֱ𱣴��Ÿ��Ե�Ӧ��״̬��application state����
һ��Web������ʵ���յ��������ʱ�Ź������Ӧ��״̬������ʱ�̣���Ĵ��ڶ���û�����塣 �����˵��ÿ���ͻ����������������ʱ���������������������������������������Ӧ��״̬������������ͻ��˷���һЩ�������ӣ���Щ���Ӵ����ͻ��˿��Լ�������������ҳ�棬Ȼ���������ͻ��˵ı��ν����ͽ����ˡ����ͻ����������������һ������ʱ����������һ�ν���������˵Web����Ӧ���ǡ���״̬�ģ�stateless������ָ�ľ��������˼�� �����ͻ���Ӧ���Լ������Լ���Ӧ��״̬��
��Դ״̬��resource state������ÿ���ͻ��˶�����ͬ�ģ���Ӧ�������ڷ���ˡ� ������Flickr�ϴ�һ��ͼƬʱ�����Ϊ��������һ������Դ������½���ͼƬӵ���Լ���URI������������URI�������� �����ͨ��HTTP����ȡ���Ļ�ɾ�������ͼƬ����Դ�� ���������˵���Դ����Ҳ���Ի�ȡ���� ��ͼƬ��һ����Դ״̬����һֱ�����ڷ������ϣ�ֱ����ɾ������
Ӧ��״̬��ʱ�ᱻ���ڷ����������ij��ϡ� ����Web���������ע��һ����Ϊ��API key����Ӧ��key����Ψһ�ַ�������Ҫ�����ÿ�����������key���������������Ϳ���ͨ�����key������һ�����Ͷ��ٴ����� ���磬Google SOAP��������Google�����ø÷���API key��һ���������1000������ һ��keyһ�췢��������������ǿͻ��˵�״̬��ÿ���ͻ��˶���һ���� һ��������������������ƣ����������Ĵ��������������仯����ĵ�1000��������Գɹ���ȡ��������ݣ�����ĵ�1001�����õ�������Ϣ��
���ͬʱ���Ҳŷ�����402���������Է�������ȻΪ�ҷ���
��Ȼ�����������������ͻ����Լ����桰�����������һӦ��״̬��application state������Ϊ�ͻ����п��ܹ��ⱨ�����֣�����ƭ�������� ������������Լ������Ӧ��״̬�Ļ����ͻ�Υ����״̬�ԣ�statelessness��ԭ�� �����API key��ͬǰ���Ǹ�RailsӦ�����_session_id cookie���������ڻ�ȡ�����ڷ������˵Ŀͻ��˻Ự����Ч��Ϊ1�죩�ļ���key���� ����һ���̶���ûʲô���⣬���������¿������ԣ�scalability�����⣺����÷��ֲ��ڶ�̨�����ϣ���ô��Ⱥ�е�ÿ̨��������֪�����㷢�����ǵ�1001�������ҷ������ǵ�402���������л�������лỰ���ƣ�session replication�������У�ֻ������������ÿ̨������֪��Ӧ�á��ܾ�������������ҵ����� ��һ�ַ����Ǹ��ؾ���ϵͳҪȷ�����������ÿ������ÿ�ζ��ü�Ⱥ���ͬһ̨���������������л�������лỰ��Ե�ԣ�session affinity������ ��״̬�Խ������ЩҪ�� ������Ϊһ����������ߣ�ֻ�е������Դ״̬��Ҫ�����ֵ���ͬ������ʱ�������Ҫ�������ݸ��ƣ�data replication�������⡣
���ڱ��������Ϣ���뿴����ٷ���վ��http://restfulwebservices.cn/

 [����] W3CHINA.ORG������ - �������������������塤RDF��OWL ��
W3CHINA.ORG������ - Web�¼������� �� �� Web Services & Semantic Web Services �� �� ��RESTful Web Services ���İ桷���� ���� ��ǰ�ԡ�
[����] W3CHINA.ORG������ - �������������������塤RDF��OWL ��
W3CHINA.ORG������ - Web�¼������� �� �� Web Services & Semantic Web Services �� �� ��RESTful Web Services ���İ桷���� ���� ��ǰ�ԡ�



 (���ı���)
(���ı���)





 ����
����  ��RESTful Web Services ���İ桷���� ..(18754��) �� admin��2008��5��16��
��RESTful Web Services ���İ桷���� ..(18754��) �� admin��2008��5��16�� ���� ���� лл!!(16��) �� jacken��2008��8��23��
���� ���� лл!!(16��) �� jacken��2008��8��23��
 ������
������